
藍(lán)鯨最前線|浙江大學(xué)熊蓉:從專家建模到數(shù)據(jù)驅(qū)動(dòng),具身智能人形機(jī)器人落地的五大挑戰(zhàn)
藍(lán)鯨新聞5月7日訊(編輯 李夢琪)從簡單的工業(yè)自動(dòng)化發(fā)展到具身智能,智能化發(fā)展進(jìn)程大步向前。人類對于智能技術(shù)的應(yīng)用早已不滿足于單一技術(shù)的重復(fù),在大規(guī)模數(shù)據(jù)積累和技術(shù)突破的當(dāng)下,人形機(jī)器人的發(fā)展逐漸從科幻走向現(xiàn)實(shí)。
浙江大學(xué)求是特聘教授、浙江人形機(jī)器人創(chuàng)新中心首席科學(xué)家熊蓉在2025藍(lán)鯨“人形機(jī)器人“高端閉門研討會(huì)上分享了具身智能機(jī)器人發(fā)展挑戰(zhàn)以及落地進(jìn)展,藍(lán)鯨新聞在現(xiàn)場獨(dú)家對話熊蓉。
浙江人形機(jī)器人創(chuàng)新中心成立于2023年,發(fā)展核心便是圍繞著打造一個(gè)能夠智能作業(yè)的具身智能人形機(jī)器人進(jìn)行展開,熊蓉希望賦予人形機(jī)器人可泛化、高精準(zhǔn)的移動(dòng)作業(yè)能力和快速便捷的開發(fā)部署能力。
通過諸多行業(yè)應(yīng)用調(diào)研,浙江人形機(jī)器人創(chuàng)新中心不斷推進(jìn)打造人形機(jī)器人本體和大小腦相關(guān)軟件算法。尤其是在機(jī)器人的操作技能上,依托具身智能相關(guān)技術(shù)賦予機(jī)器人多場景下可泛化、高精度和高可靠的操作能力。據(jù)熊蓉介紹,早在去年8月份,旗下人形機(jī)器人已經(jīng)實(shí)現(xiàn)在雙腳直立的情況下做大幅度擬人的動(dòng)作、操作工具實(shí)現(xiàn)高精度操作任務(wù)(如打螺絲)以及開放雜亂場景下的端到端自主決策任務(wù)(如端茶倒水)。

浙江人形機(jī)器人創(chuàng)新中心于2024年發(fā)布首代產(chǎn)品領(lǐng)航者二號,它的手臂作業(yè)能力可以達(dá)到5公斤的負(fù)載和0.1毫米的精度
她表示這兩年產(chǎn)業(yè)界和科技界的兩大熱點(diǎn)詞匯是具身智能和人形機(jī)器人,但從最終發(fā)展視角來看,其實(shí)要打造的是能夠具身智能作業(yè)的機(jī)器人,人形機(jī)器人代表一種通用的形態(tài),能夠更好地去適應(yīng)人類生存的環(huán)境。藍(lán)鯨最前線欄目獨(dú)家整理熊蓉在會(huì)議上的分享內(nèi)容,以下:
一、人形機(jī)器人是具身智能最大的挑戰(zhàn)者
當(dāng)具身智能和人形機(jī)器人交融的時(shí)候,它能夠形成我們期望的多功能的機(jī)器人,去取代原來基于某個(gè)特定任務(wù)打造的專用機(jī)器人。
近兩年,國內(nèi)外對于人形機(jī)器人的市場預(yù)測越來越樂觀,去年11月份,花旗銀行發(fā)布預(yù)測報(bào)告,預(yù)計(jì)人形機(jī)器人相關(guān)產(chǎn)業(yè)在2030年能夠達(dá)到百萬的市場,到2050年在整個(gè)機(jī)器人市場占有率排位第三。
人形機(jī)器人能不能落地,關(guān)鍵在于具身智能技術(shù)。早在上世紀(jì)50年代,圖靈就給出了具身智能的定義,核心在于通過行為表現(xiàn)而非內(nèi)在機(jī)制來判定機(jī)器是否具備智能?。之前計(jì)算機(jī)、人工智能的發(fā)展,我們更多關(guān)注的是感知智能,它不需要跟物理世界發(fā)生接觸,通過語言、文本、圖像、視頻,我們就能夠?qū)锩娴奈矬w進(jìn)行認(rèn)知。
現(xiàn)在技術(shù)正由專家建模求解轉(zhuǎn)為數(shù)據(jù)驅(qū)動(dòng)學(xué)習(xí)訓(xùn)練,由模塊解耦分離轉(zhuǎn)為感控一體端到端。為什么會(huì)發(fā)生這樣的改變?因?yàn)閭鹘y(tǒng)專家的知識經(jīng)驗(yàn)只在限定框架內(nèi)適用,一旦超出范圍就不適用。因此,我們在傳統(tǒng)機(jī)器人使用中經(jīng)常看到,換一個(gè)場景、換一個(gè)作業(yè)任務(wù),需要專家不斷地介入或進(jìn)行參數(shù)調(diào)整。
面對現(xiàn)實(shí)中的各類復(fù)雜場景,我們可以通過積累數(shù)據(jù)形成現(xiàn)在通用的語言大模型、多模態(tài)大模型,希望通過行為數(shù)據(jù)的不斷積累,能夠讓它具備行為智能。
通過具身智能技術(shù),我們可以去讓機(jī)器人適應(yīng)更多的場景,減少對專家知識的依賴。同時(shí)還有一個(gè)重要意義,當(dāng)我們做感控一體端到端方案的時(shí)候,能夠降低對感知準(zhǔn)確性的影響。當(dāng)前大模型的泛化性足夠,但存在準(zhǔn)確性不夠的問題。如何提高感知準(zhǔn)確性、讓行為保持正確是我們需要解決的問題。
作為通用形態(tài),人形機(jī)器人將會(huì)面臨更多的作業(yè)對象和場景。又因?yàn)樗旧淼淖杂啥忍貏e高,全身的自由度通常大于30個(gè),而且運(yùn)動(dòng)模式多,在這些情況下面,我們其實(shí)很難用傳統(tǒng)的專家建模、機(jī)理控制的方式去做,所以我們說人形機(jī)器人是具身智能最大的需求者。同時(shí)因?yàn)樗貏e復(fù)雜,從而也使得它成為具身智能最大的挑戰(zhàn)者。
二、人形機(jī)器人為什么這么火熱?
人形機(jī)器人的火熱來源于社會(huì)發(fā)展需求和技術(shù)發(fā)展支撐兩方面因素共同推動(dòng)。
一是社會(huì)發(fā)展需求。人口老齡化問題正逐漸成為國內(nèi)外面臨的一個(gè)重要問題,如生產(chǎn)制造、康養(yǎng)護(hù)理等領(lǐng)域均需要有機(jī)器人來補(bǔ)充空缺勞動(dòng)力。
傳統(tǒng)工業(yè)機(jī)器人已經(jīng)在工業(yè)自動(dòng)化中發(fā)揮了極大作用,現(xiàn)在工業(yè)自動(dòng)化還需要大量應(yīng)用人的雙臂手,甚至有些場景需要調(diào)動(dòng)全身協(xié)同能力完成,這要求機(jī)器人具備較強(qiáng)的在有限空間內(nèi)進(jìn)行靈巧作業(yè)的能力。當(dāng)前已經(jīng)投入應(yīng)用的專用機(jī)器人并不非不能用,但需要將功能拆解為多臺機(jī)器人完成,占用的空間比較大。尤其是在柔性生產(chǎn)制造方面,還需要依賴專家編程,因此目前發(fā)動(dòng)機(jī)、底盤、電氣、裝飾等裝配工序90%以上仍需要人完成,組裝需數(shù)小時(shí)到數(shù)十個(gè)小時(shí)不等。
社會(huì)發(fā)展亟需把人形機(jī)器人和具身智能技術(shù)結(jié)合,打造新型通用作業(yè)機(jī)器人。這其中,具身智能是重要技術(shù)基座,可降低專家編程依賴,提升自主適應(yīng)能力。
對于未來康養(yǎng)護(hù)理、家庭服務(wù)機(jī)器人來講,最佳的形態(tài)也是人形機(jī)器人,但是它面臨著場景、任務(wù)多以及可復(fù)制性等等問題,這些都對具身智能提出了一個(gè)極大的需求。
二是技術(shù)發(fā)展支撐。隨著大模型、生成式AI、合成數(shù)據(jù)、大算力等技術(shù)創(chuàng)新,具身智能技術(shù)進(jìn)入到了一個(gè)新的階段。這兩年具身智能技術(shù)的發(fā)布層出不窮,可以總結(jié)為兩大類:
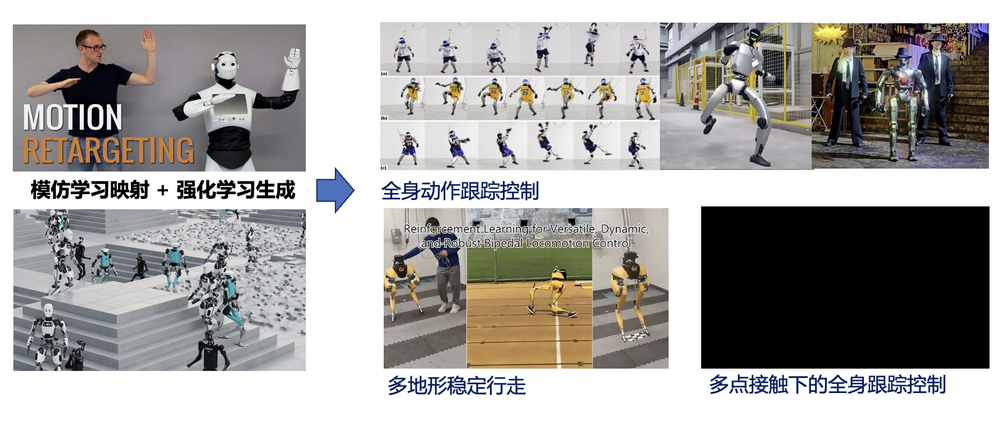
一類是人形機(jī)器人擬人化魯棒運(yùn)動(dòng)能力大幅提升。用人機(jī)動(dòng)作行為映射學(xué)習(xí),加上仿真平臺里面的強(qiáng)化學(xué)習(xí),讓人形機(jī)器人有擬人化靈活的運(yùn)動(dòng)。國際上對于如何進(jìn)行全身跟蹤控制提出了多種方法,國內(nèi)宇樹也在他們的小機(jī)器人上展示了靈活運(yùn)動(dòng)能力,同時(shí)也有研究機(jī)構(gòu)在研究多地形的穩(wěn)定行走。仿真強(qiáng)化學(xué)習(xí)較好地解決傳統(tǒng)專家對機(jī)器人建模的不準(zhǔn)確、環(huán)境擾動(dòng)、無法建模等問題,有效提升運(yùn)動(dòng)的魯棒性。

一類是語言-視覺-行為大模型VLAM初步形成。從早期的谷歌語言-視覺-行為串聯(lián),到去年提出來用遙操作數(shù)據(jù)去學(xué)習(xí)長序列構(gòu)建一體化的架構(gòu),到今年的分層式架構(gòu),上層用語言視覺進(jìn)行行為決策,下層進(jìn)行上身體高速運(yùn)動(dòng)控制,并進(jìn)行兩層聯(lián)合訓(xùn)練。在數(shù)據(jù)積累的情況下,人形機(jī)器人能夠去做一些抓放、拉拉鏈等一系列工作。
三、距離真正的落地應(yīng)用還有多遠(yuǎn)?
熱潮背后,我們還要看到現(xiàn)有技術(shù)距離真正的落地應(yīng)用還是有著很大的挑戰(zhàn)。

根據(jù)去年Gartner發(fā)布的產(chǎn)業(yè)技術(shù)成熟度曲線顯示,人形機(jī)器人、空間智能、具身智能、行為大模型整體處于產(chǎn)業(yè)早期發(fā)展階段。我們現(xiàn)在正進(jìn)入到一個(gè)技術(shù)快速發(fā)展、公眾對技術(shù)期望快速膨脹的階段,但是它離真正的落地應(yīng)用還面臨著多個(gè)挑戰(zhàn):
挑戰(zhàn)一是人形機(jī)器人運(yùn)動(dòng)學(xué)習(xí)偏復(fù)現(xiàn)/遙控,尚需提升作業(yè)臂(有精度和負(fù)載)下的上肢大幅運(yùn)動(dòng)、負(fù)載作業(yè)、智能移動(dòng)作業(yè)、并滿足作業(yè)精度要求。
具體來講,我們雖然現(xiàn)在能夠做到靈活運(yùn)動(dòng),其實(shí)每一個(gè)運(yùn)動(dòng)序列都需要反復(fù)訓(xùn)練,而在里面它還是依賴專家知識經(jīng)驗(yàn)去進(jìn)行網(wǎng)絡(luò)的調(diào)參,然后來實(shí)現(xiàn)功能,所以我們看到的相關(guān)演示都是片斷式的,或者是特斯拉那種遙操作方式。
挑戰(zhàn)二是VLAM行為偏簡單,動(dòng)作類別少,缺少力觸信息融合、工具使用等。現(xiàn)有VLAM融合了視-抓-放-移,形成視覺-軌跡的端到端控制,主要為小范圍場景行為,缺少旋擰、插拔等力觸動(dòng)作、多指協(xié)同、柔性物體操作、工具使用等。
比如人形機(jī)器人在桌子上學(xué)習(xí)得到的視覺和軌跡映射,一旦變更場景就需要重新采數(shù)據(jù)、進(jìn)行訓(xùn)練,所以它的泛化性比較差。這與我們只是簡單地做感知和行為映射有關(guān)系,它并沒有形成知識的學(xué)習(xí),不具備人類知識學(xué)習(xí)和抽象泛化的能力。

挑戰(zhàn)三是交互行為學(xué)習(xí)訓(xùn)練數(shù)據(jù)匱乏。很多的應(yīng)用場景涉及到柔性物體的操作、以及工具的使用,其中很多要求都涉及到力觸等交互信息,而與互聯(lián)網(wǎng)文本、圖像、視頻數(shù)據(jù)相比,當(dāng)前機(jī)器人跟環(huán)境交互的數(shù)據(jù)非常匱乏。合成數(shù)據(jù)和仿真訓(xùn)練面臨Sim2Real問題,遙操作采集則涉及設(shè)備、人員、標(biāo)注等,成本高且異構(gòu)遷移難。
挑戰(zhàn)四是亟待突破可泛化、自適應(yīng)與高精度、高可靠、高效率的兼顧。工業(yè)發(fā)展要求高精度、高可靠、高效率,而我們現(xiàn)在的柔性生產(chǎn)制造則希望它能夠?qū)崿F(xiàn)可泛化、自適應(yīng)。
挑戰(zhàn)五是亟需提升視-力-觸傳感器、端側(cè)智能計(jì)算控制器和操作執(zhí)行器。在執(zhí)行器件方面,不管是關(guān)鍵零部件如靈巧手、環(huán)境交互的傳感器以及端側(cè)計(jì)算設(shè)備,均需要進(jìn)一步提升性能,包括體積重量減少,精度、可靠性、壽命的提升等。
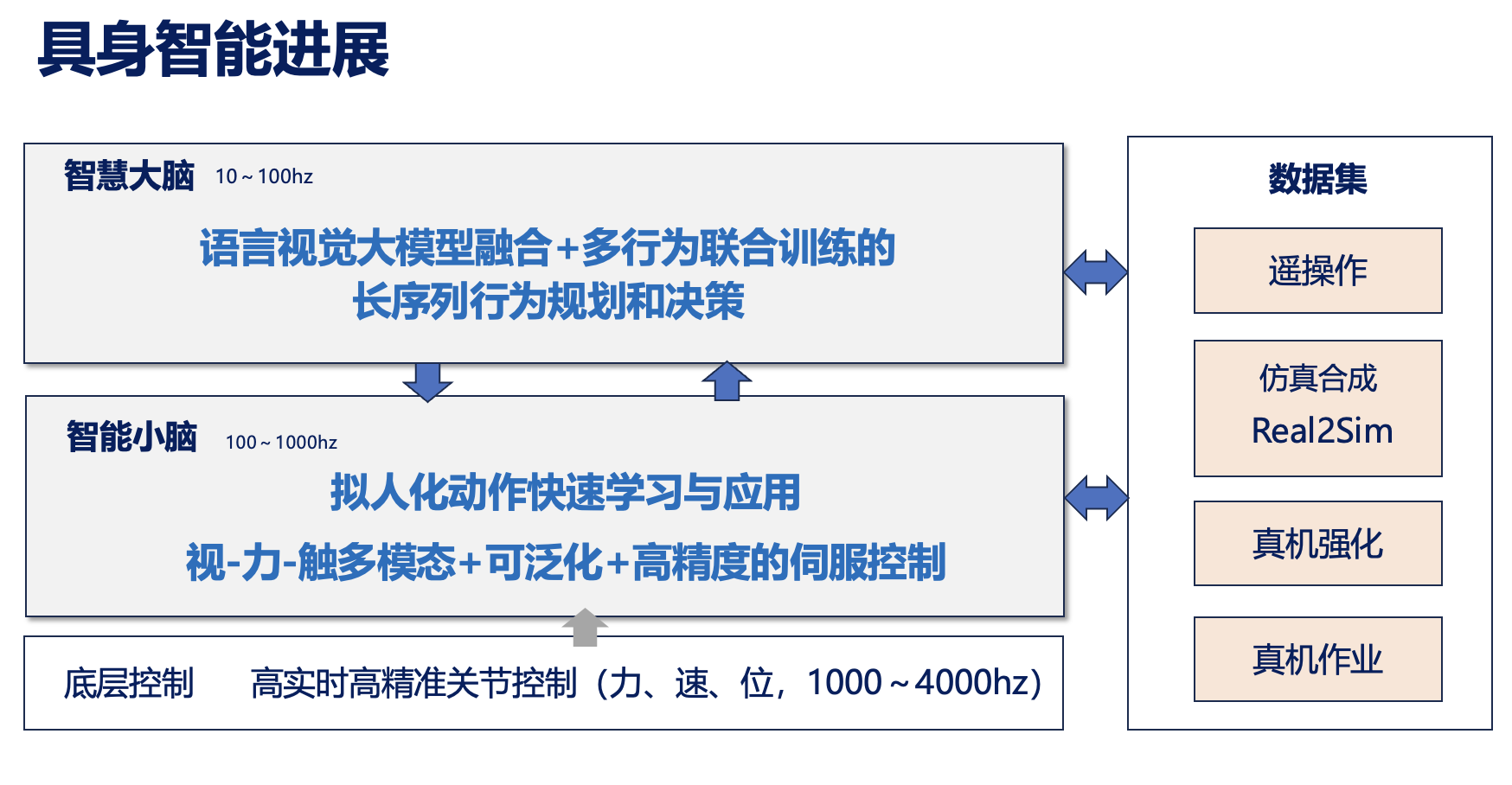
浙江人形機(jī)器人創(chuàng)新中心也從不同方面推動(dòng)人形機(jī)器人及具身智能發(fā)展。在具身智能方面,我們在大小腦和數(shù)據(jù)采集方面做了一系列的工作,特別是提升機(jī)器人的操作技能。通過底層高實(shí)時(shí)、高精準(zhǔn)的控制,能夠?qū)崿F(xiàn)大幅的運(yùn)動(dòng)和高保真,讓人形機(jī)器人在雙腳直立的情況下做大幅擬人的動(dòng)作,以及操作工具實(shí)現(xiàn)高精度操作任務(wù)等,這是在去年8月份實(shí)現(xiàn)的。
目前的技術(shù)有多方面進(jìn)展:運(yùn)控方面,可以實(shí)現(xiàn)高實(shí)時(shí)高精準(zhǔn)下的長序列新動(dòng)作快速學(xué)習(xí);操作方面,可以實(shí)現(xiàn)雙臂-手-頭協(xié)同的遙操作,軌跡更平滑、延遲較低,與此同時(shí),還搭建了場景可泛化的Real2Sim2Real訓(xùn)練通道;可泛化高精準(zhǔn)視覺伺服技術(shù),可適應(yīng)無標(biāo)定、擺放誤差、抓工具誤差等問題,可適應(yīng)少紋理場景……
未來人形機(jī)器人的想象空間還有多大?從工廠流水線操作到零售場景到家庭服務(wù)等等,新的應(yīng)用場景探索還在隨著技術(shù)進(jìn)步不斷向前推進(jìn)。

